在現代分布式微服務架構中,定時任務的執行面臨著新的挑戰:如何確保一個本應在整個系統內只執行一次的定時任務,在由多個獨立部署、可能隨時擴縮容的微服務實例組成的集群中,不被重復執行?這正是分布式調度框架需要解決的核心問題之一。ElasticJob作為一款優秀的分布式任務調度解決方案,為此提供了優雅且強大的支持。
一、基本概念介紹
1. 分布式調度與ElasticJob
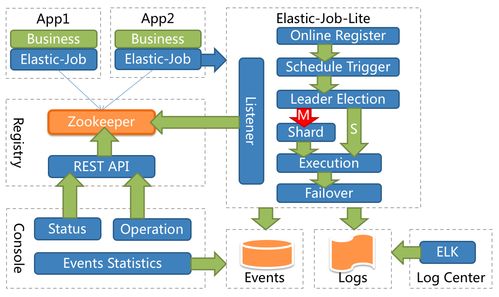
分布式調度是指將任務調度邏輯從單臺服務器擴展到多臺服務器(節點)組成的集群中。ElasticJob是一個開源的分布式調度框架,源自當當網,后進入Apache ShardingSphere生態。它通過協調集群中的多個實例,能夠實現任務的動態分片、故障轉移、錯過任務重觸發等高級功能。其核心目標是讓分布式定時任務像在單機上一樣易于管理和可靠運行。
2. “多個微服務執行,只需執行一個任務”的場景
假設我們有一個“每日數據匯總報表生成”的定時任務。在由10個相同微服務實例構成的集群中,我們顯然不希望每個實例都在凌晨2點同時執行這個耗資源的任務,生成10份相同的報表。我們期望的是:無論集群中有多少個實例,這個任務在任何一個調度周期內,有且僅有一個實例成功執行一次。這就是典型的“單例任務”或“冪等任務”在分布式環境下的執行需求。
3. 實現原理:協調與選舉
ElasticJob實現上述能力主要依賴于兩個關鍵組件:
- 注冊中心(ZooKeeper或Nacos等):作為協調者,存儲作業配置、運行實例信息和分片項。它是所有服務實例共享的“公告板”和“協調器”。
- 作業分片(Sharding)概念:即使任務本身不需要并行處理(即只需要一個實例執行),ElasticJob也將其視為一個總片數為1的作業。多個服務實例在啟動時,都會向注冊中心注冊自己成為“作業實例”。
其執行流程可以簡化為:
- 任務觸發:到達預設的Cron時間點,或由其他事件觸發。
- 主節點選舉:ElasticJob框架會在當前所有在線的作業實例中,自動選舉出一個“主節點”(Leader)。這個選舉過程通過注冊中心(如ZooKeeper的臨時順序節點)的原子操作實現,確保只有一個實例被選為主節點。
- 分片分配:主節點負責計算并分配任務分片。對于我們的單例任務,總片數就是1片。主節點會將這唯一的1片分配給自己或另一個活躍的實例(取決于配置和策略)。
- 任務執行:被分配了分片(即第0片)的那個實例,開始執行具體的業務邏輯。其他未被分配分片的實例,則在本調度周期內處于“空閑”狀態。
- 故障轉移:如果正在執行任務的實例在運行中宕機,注冊中心會感知到其連接斷開。主節點(或重新選舉出的新主節點)會在下次調度時,或者通過監聽機制立即將未完成的分片重新分配給其他健康的實例執行,從而保證任務最終被完成。
二、與信息系統運行維護服務的關聯
將ElasticJob應用于信息系統運行維護服務的定時任務場景,能極大提升運維的自動化程度和可靠性:
1. 高可用與容災
傳統的單點定時任務(如Linux Cron)存在單點故障風險。ElasticJob分布式部署使得“定時任務”本身成為高可用的服務。即使某個微服務實例宕機,任務會自動由其他實例接管,確保關鍵的運維任務(如日志歸檔、證書續期、監控數據清理)不會因單點故障而遺漏。
2. 彈性伸縮與資源優化
在微服務架構中,實例數量會根據負載動態調整。ElasticJob能夠動態感知實例的上線和下線,并重新協調任務分配。運維任務不會因為集群擴容而重復執行,也不會因為縮容而丟失,實現了計算資源的優化利用。
3. 統一管理與可視化
ElasticJob-Console等運維控制臺提供了作業狀態、歷史記錄、配置修改和手動觸發等集中管理功能。這對于運維團隊來說,意味著可以在一個統一的界面監控和管理所有分布式環境下的定時運維作業,替代了原先需要登錄多臺服務器查看Cron日志的繁瑣方式。
4. 典型運維任務場景示例
- 數據清理任務:每日凌晨清理臨時表或過期日志文件,只需一個實例執行即可。
- 監控告警聚合:每5分鐘匯總一次各服務的健康狀態并發送報告。
- 數據庫備份狀態檢查:定時檢查分布式數據庫各分片的備份是否成功。
- 緩存預熱:在系統低峰期,由單一實例負責觸發全集群的緩存預熱邏輯,避免所有實例同時預熱造成沖擊。
###
ElasticJob通過引入注冊中心進行協調和主節點選舉的機制,巧妙地解決了在分布式微服務環境中“多個實例競爭,一個任務執行”的難題。它將分布式環境下的任務調度抽象化、服務化,使得開發者和運維人員能夠以接近單機任務的思維模型,來管理和運行高可用、彈性的分布式定時任務。將其集成到信息系統的運行維護服務體系中,不僅能提升運維任務的可靠性和自動化水平,也符合云原生架構下應用狀態與業務邏輯分離、通過聲明式進行管理的最佳實踐。